I have created a script to pull incoming records to a database and post them to another dbase via REST. I have everything working, however I have one hurdle. The source table is very large and I’d like to simply query only new records since the last run of the script. How can I keep track of either the timestamp I ran the last query or the last key number so I can only get the new records?
I don’t see a way to assign a “global variable” or something of the type that could hold this info. The only other solution that seems possible is to write this info into a file and read it back, but I don’t see how to do this either.
I am very new to the product and absolutely love it so far, but I may just be missing a very fundamental function here.
Linx does not have a concept like global variables. Linx Services e.g. TimerService, are the only Linx components that can keep state outside of process execution.
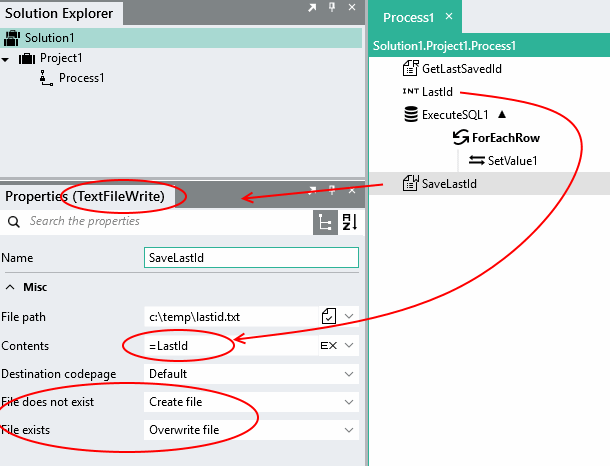
You will need to keep your state in persistent storage like a file, database, s3 bucket etc. Here is a sample of keeping the last id in a file. The process
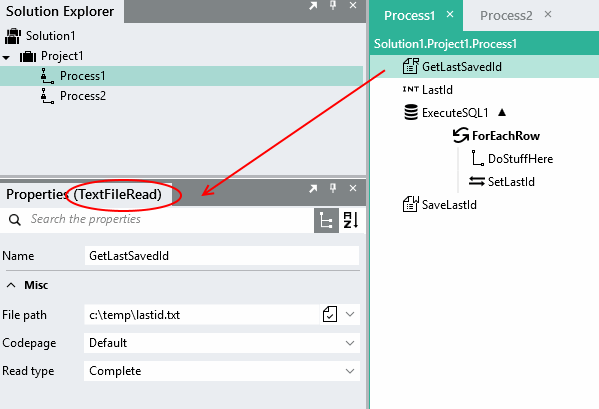
Reads the last saved id from a text file using the TextFileRead function.
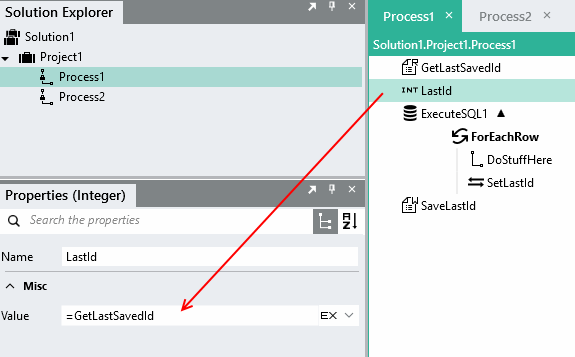
Creates a variable that stores the last id read from the database using an Integer type.
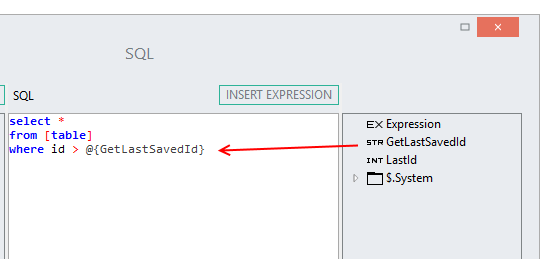
Reads the database referring to the last saved id to limit the records returned.
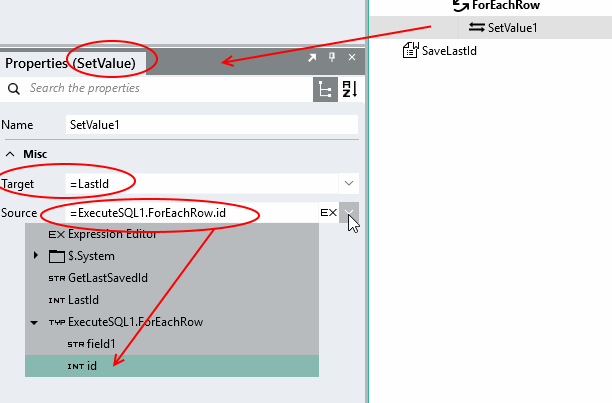
Sets the last id variable to keep track of the last id processed.
When finished, saves the last id to file using a TextFileWrite.
Some screenshots to illustrate:
1.Read the last saved id from a text file using the TextFileRead function.
2.Create a variable that stores the last id read from the database using an Integer type.
3.Read the database referring to the last saved id to limit the records returned.
4.Set the last id variable to keep track of the last id processed.
5.Saves the last id to file using a TextFileWrite.
Another option
Depending on your scenario, you can also query the target database for the last id or timestamp inserted and then use that to limit the rows returned from your source database. That will mean saving the id and/or timestamp in the target but then the requirement for the file will go away.
Linx is kind of “State-less” if that’s the correct term… In itself it does not keep any values. It is good that way because it makes sure that you are not limited with your solution to a specific computer. You can run the same solution on different servers / computers without having to worry about data that needs to be copied over.
Thus, not knowing completely what your scenario is, but assuming you’ve got enough rights on the database to which you’re writing to, I would propose that you do not save the ID to a file or any local setting. The same issue will occur, where if you ever want to move your solution to another PC, you’d need to also remember the file.
So I’d propose the following:
Identify the incrementing identifier on the source table. (for the example I’ll call it “ID”)
On the target table have a new column named “SourceID”.
When writing to the target table, also write “ID” to “SourceID”. (Remeber, the target table’s auto- incrementing identifier may not always be in-sync with the source), thus I’d explicitly write “ID” to “SourceID”.
Before running the batch every day (or interval as chosen) get the last SourceID saved:
Select top 1 SourceID from [TargetTable]
order by SourceID desc
Then do the select on the source table using the “SourceID” as reference:
Select *
from [SourceTable]
where ID > @{SourceID}
Doing it this why you never need to keep record of the last retrieved ID, because the system will do it itself anyway.